
{hhr, 200107}
- autonomous improvisation
- water marking; by-passing; passing through
- P systems
Is there any way we could inject something at node n that can be decrypted at node n + 2 ? It seems hardly possible. At most we have an extremely low frequency of information flow, and so we could encode that through temporal pattners, trying out with a known dictionary how to encode them.
This can only remain a hypothesis until we have a first running system; thus probably very late.
What would be global knowledge?
- wall clock (if we set it so)
- the "existence of others"
So, for example, wall clock could be used to know when we tune to particular frequencies?
Remember Biphase Mark Code? Acoustic coupler.
- - - -
So can we find a way that is not about friend/foe, bypassing in order to deceive, but so that each row has a double-interpreter; one for that immediate signal from the neighbouring machines, and one for the "improvisatorily" recovered signal from further away.
{keywords: [_, autonomy, improvisation, p system, marking, encryption, flow, hypothesis, knowledge, clock, frequency, interpretation, neighbour, signal]}


{hhr, 200330}
Things to look at:
- P systems
- (Bayesian networks)
- Graph transformation theory, graph rewriting
{keywords: [p system, network, graphs]}

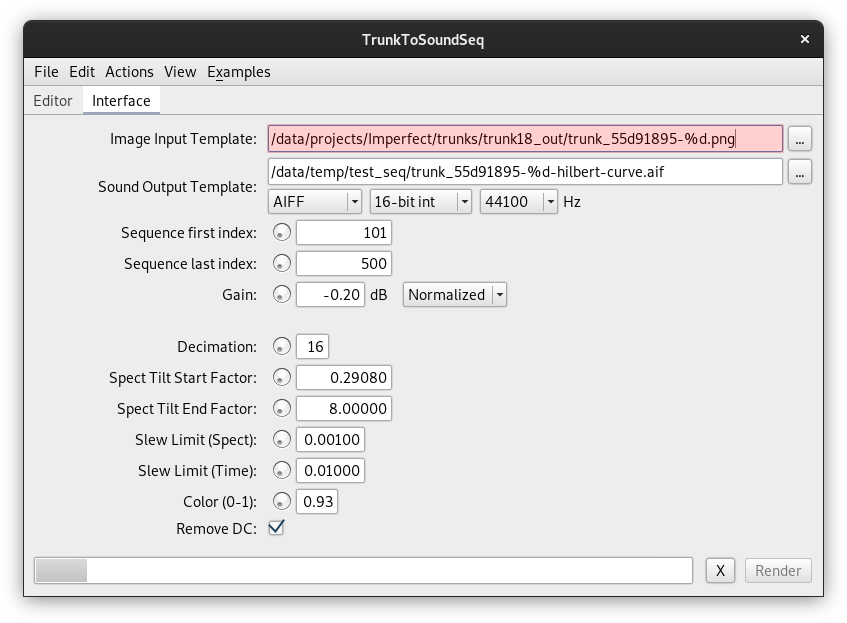
Program to translate the video miniatures 'Trunk' to synthetic sounds suitable as targets for the GP process. 'Trunk' is a strange object that floats in my head ever since I recorded the cut branch trunks from Los Galpones, Caracas, on wax paper in anticipation of a sound installation there (which was never realised as such). The dozen or so wax paper images have been digitally scanned and reworked using a cartesian-to-polar transformation into infinite white-on-black video sequences, making it into the series 'Inner Space' as one of its elements.
The translation process into sound took a number of attempts that were all unsatisfying, until somebody suggested to look at space-filling-curves. Using the known Hilbert curve, I found an acceptable way of scanning the two dimensional video frames, and using a combination of time and spectral signal, we get distinctly coloured sounds that all share the same characteristic as if scratching over slightly resonant metallic surfaces, still quiet crisp. Despite the scanning procedure, the frame-by-frame correlation of the sounds is quite large. If one assembles them with the same frame rate as the video, one hears a 25 or 30 fps mechanical reproduction. For in|filtration, though, the sounds are taken as individuals, where the GP moves from frame to frame as it proceeds with its own iterations.
Code.
{hhr, 200624}
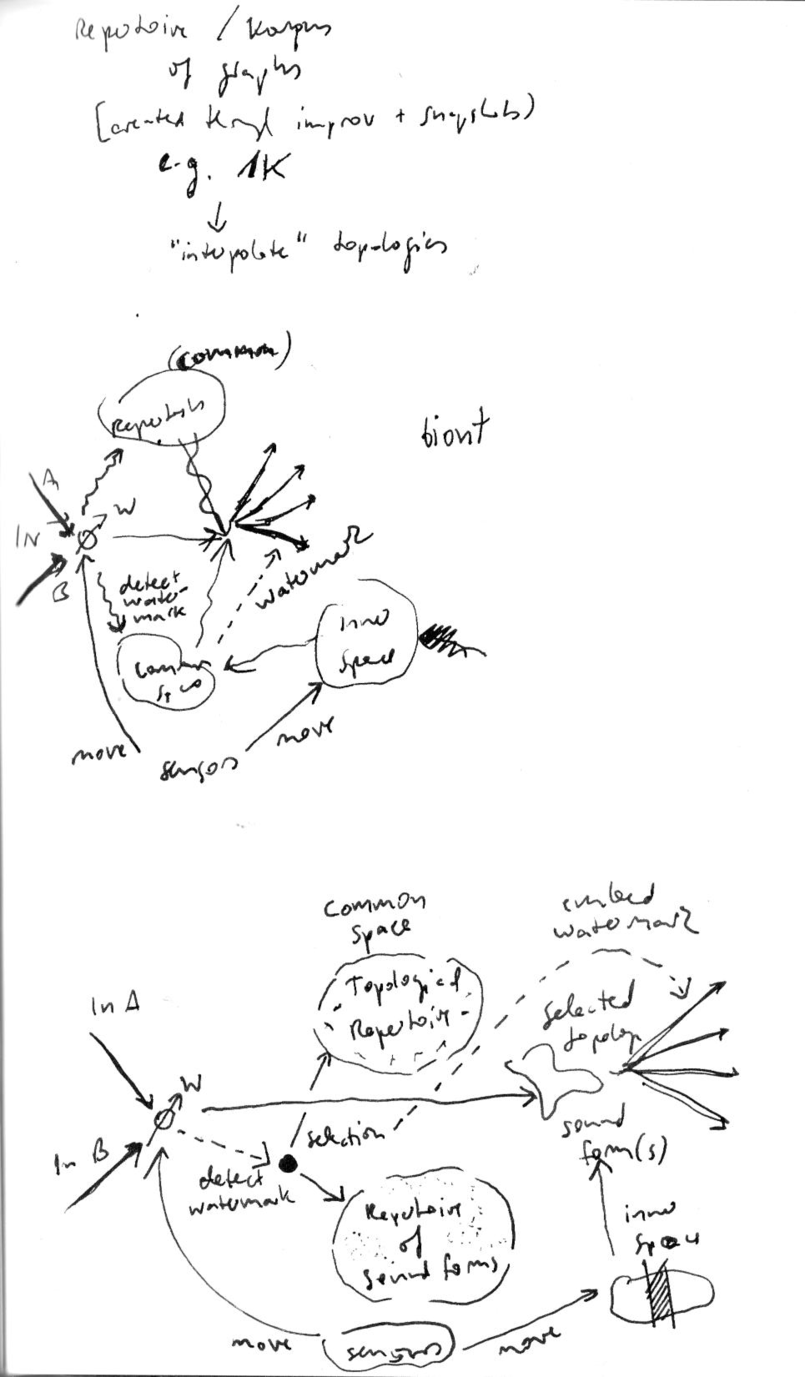
The above drawing was made as a realisation of how the piece could be composed. As some of its meaning is escaping my memory, I will try to reformulate the components as text.
First, there is the distinction between a c ommon space and an individual (or inner) space. The common space is what is shared as structure between the six nodes. This is a repertoire of forms. First, forms of topology in the sense of a Wolkenpumpe sound situation, a graph of connected nodes. Second, forms of synthetic sound, which are obtained through genetic programming. The individuation has two aspects; a given identity in the form of a "trunk space", and a reflected identity through the introduction of sensor data. Furthermore, a movement of commoning between individuals due to the attempt to share a position marker.
The genetic programming departs from the Negatum project, using a "moving target" across iterations. As in Configuration and others, there is a selection process for sound forms from each iteration. Furthermore, we want to constrain the unit generators, either a priori (this is not indicated in the image), or posteriori using a graph transform (e.g. aliasing multiple unit generators). The set of unit generators could perhaps emphasise the characteristics of the space, such as the visual material used and the idea of filtering (subtractive). The image does not indicate what the target sound is. Nor how the corpus is organised (possibly as a self-organising map according similar to Configuration, or a minimum spanning tree as in schwärmen). An important additional step is the parametrisation of the sound forms. The parameters are then coupled to the trunk space, which in turn is a visual scanning, similar in gesture but with individual trunks for each node. The scanning of the trunk space itself is done by the sensor signals.
We move from topology to topology and sound form to sound form. How? There is an interpolation, that "renacts" what happens in an improvisation. Ideally, nodes will be able to share positions and thus "align" their sound spaces. Otherwise, they will be slowly drifting.
{group: sketch2}
{hhr, 200327}
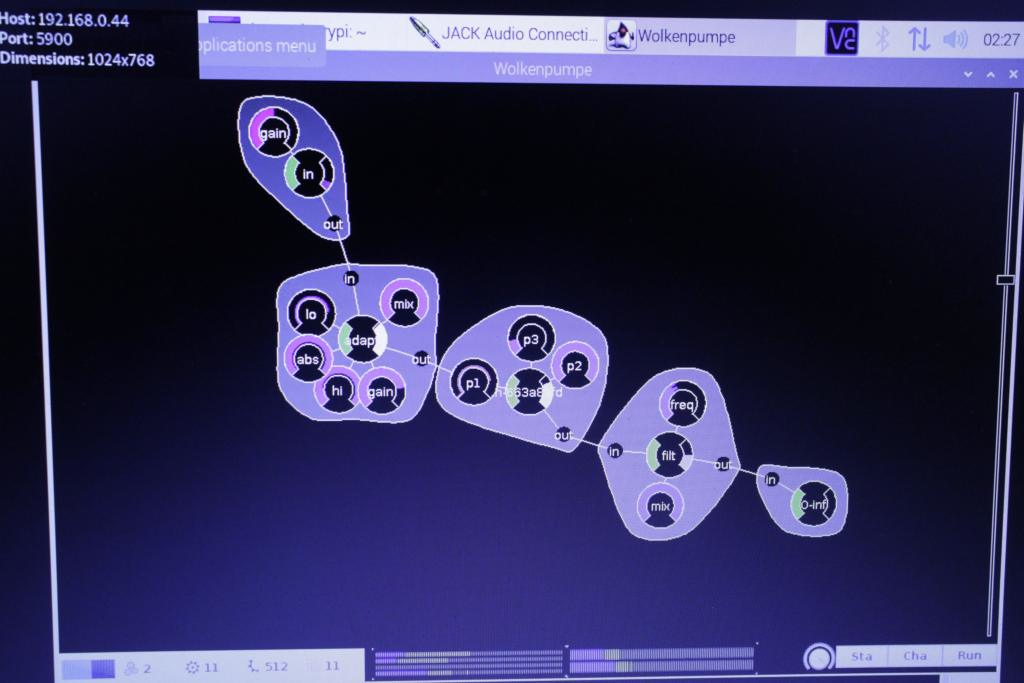
How could I put the systems made for improvisation – Wolkenpumpe – to develop structures on its own? And what does it mean to multiply this process over six independent nodes?
{kind: caption, group: nuages, keywords: [_, Wolkenpumpe, improvisation]}

{hhr, 200624}
In order to begin the GP—which takes long time, and thus needs to be started asap—the target sound needs to be known, as well as the shifting implemented, and the set of UGens chosen. The parametrisation can be developed thereafter, while the GP is running on other computers.
I wonder if I had any target in mind when I drew the image?

{hhr, 200629}
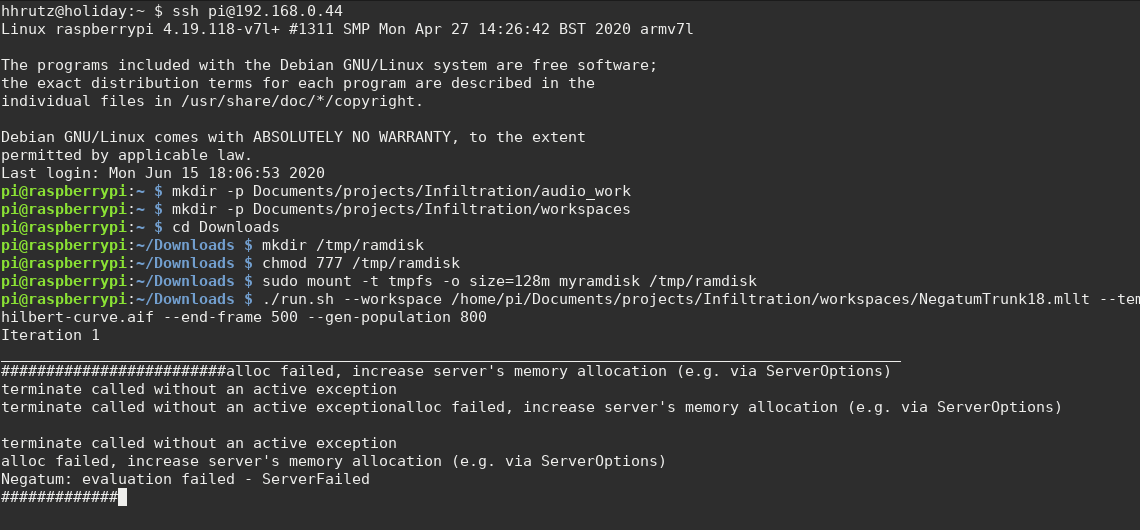
After revising the Negatum library for genetic sound programming, I started to put some of the Raspberry Pis to work on their individual set of target sounds. I.e., there are six sets of trunk sounds for the six nodes that will be running my system in the installation. I limited the set of UGens to exclude any regular or chaotic oscillators expect for pulse waves, aiming to narrow the sonic outcome to more closely match the idea of the space and the filtering. (After some iterations running now, it seems indeed that the sounds encircle a particular kind of timbre space). I also patched the "allowed ranges" for the remaining oscillators, so that there won't be any fundamental frequencies higher than 60 Hz, although the GP of course will find other ways to introduce higher pitched sounds (for example, narrowing the volume of the virtual space of a reverberation, producing resonant filters etc.)
So far, the Pis are running fine, after a few fixes (the screenshot shows still an older run), there seem no longer problems with dangling 'scsynth' instances, memory leaks, crashes etc. The six units are roughly as fast as my laptop, I would estimate; not amazingly fast, but fast enough to produce 100 to 500 iterations over the weeks, and freeing up the laptop for other work.
{hhr, 200701}
To obtain parametrisation, the simplest approach is to try to replace the constants in a UGen graph. Looking at the parameter range constraints already in place, we can create a logarithmic scale of a given number of values to cover the possible value range, and then systematically bounce the variations of each individual parameter to look at the effect in the sound—probably looking at the amount of dissimilarity between two pairs of sound variants, also taking care of "vanishing" sounds (as they may become quiet). Below we test 31 values (the 32th value is the "original" value of the genetic program).