Context Boundaries
This project and the explored threads all feature a set of components that contribute to a collective whole. The starting point is usually digital sound synthesis. It is followed by sound analysis and windowing of that information. Analysis data is then gathered, stored, processed and submitted to a learning algorithm. Once a model has been trained, it is used in a performative mode that involves providing input, receiving output and interpreting it via compositional algorithms. The collective whole also features visual representations of the process, interfaces and post-processing of sound.
I understand all of these parts as belonging together through the context and their environment that encapsulates the technical actors and where “knowledge is always interpretation, and thus located in a perceiving entity whose position, attitudes, and awareness are all constituted in a codependent relation with its environment.” (Drucker 2009.) The context here covers the stored data, how it is represented and what processes are applied. The environment refers to the chosen set of algorithms and the scope within which the whole process takes place. The concept of “environment” is therefore internalised, encompassing the network of algorithms, musical material and the dynamic interactions it facilitates.
Each of my system components holds interaction potentials that come about through its boundary conditions. These boundaries, whether concrete, porous, or fuzzy, define how a component engages with its context and other components. For example, coupling strength is critical in determining how a change in one component affects another. The concept of modularity is also contrasted with systemic overlap, where components with clear boundaries and stable interactions coexist with those exhibiting more fluid, less defined connections. These overlapping and transitive relationships between components introduce data flows, driving the organisation and evolution of the system over time.
Algorithms, while essential for implementing specific processes, exist as distinct entities within the system. They contribute to its function but operate in relation to the broader infrastructure, interfaces, and interactions that define systemic behaviour. This interdependence of algorithms and systems highlights the creative and technical processes explored here, revealing the potential of machine learning to mediate complex but interconnected technical approaches.
The data gathering and learning processes combined with the sonic approaches, their context and environment form the backbone of this project. The artistic research project that follows and is covered here is motivated by three main research questions:
-
How can integrating machine learning with algorithmic composition techniques enhance the compositional process of computer music, and what knowledge can be produced from this fusion?
-
How can the utilisation of data obtained through the creative process itself, as opposed to pre-existing datasets, inform and enhance the training of machine learning models in computer music?
-
How can live coding and sound synthesis be a foundation for exploring machine learning models and guiding their behaviour?
I attempt these questions through the four threads and projects covered in the following text.
Learning Process
The process of training machine learning systems for computer music involves balancing precision and intuition where the artist's role becomes one of configuring a system to learn and evolve based on the input data. Unlike traditional programming, where a solution is usually explicitly implemented, working with machine learning algorithms often involves finding the context within which a system can achieve desired outcomes and where “one does not attempt to directly implement a solution to the problem at hand but rather to create the right conditions for the machine learning system to accomplish target tasks” (Audry 2021). This requires a careful reading of the data, a critical selection of algorithms, and constantly refining the training process.
The first step in the learning process usually involves defining the type of learning task. For example, a choice of supervised, unsupervised, or reinforcement learning. Each approach dictates how the system interacts with the data and the kinds of outcomes it can produce. Different implementations have been implemented and tried in the four approaches that make up this project: supervised and unsupervised. Later, during the learning process, information about error rates and the accuracy of learning becomes available. This can serve as an indication of whether the process is progressing well or not.
However, this conceptual separation of the steps in the process is also to be questioned, as mentioned by Doebereiner and Pirró: “The training phase is therefore regarded as a preparatory step that is carried out with a view to optimal generalization for another task. The memory is built and later activated.” (Döbereiner, Pirró 2024). This separation creates a disconnect, particularly in creative applications like music, where the "memory" built during training remains static during performance. The dynamic nature of live sound often demands real-time adaptation and learning, a capability typically absent in a pre-trained, fixed model. In most cases, machine learning algorithms usually don’t offer much control after having been started and can primarily be understood as “black boxes” where, once trained, their inner workings can become difficult to interpret. The generalized models additionally pose problems of homogeneity and lack of novelty where they “generate ‘more of the same’ content, causing two complementary issues: fostering reconstruction instead of extrapolation, and leaving their behavior in extensional cases unexplored.” (Chemla–Romeu-Santos, Esling, 2020).
From another perspective, the black box can also become an active participant in the creative process, generating results that are not entirely predictable yet are shaped by choices during training and the interpretation of the resulting model output, where it can be seen as “a box that has become an integral feature of composition systems and some musical instruments” and where “algorithms thus become actors in our music making that need investigation.” (Magnusson 2023). Black boxes challenge the notion of direct control, introducing an element of autonomy that questions the relationship between the data and the tool that is being used.
Evaluation and refinement are iterative stages that connect the training process to the final output. Metrics like loss functions and accuracy provide quantitative feedback, but the real test involves observing the system’s behaviour. The sonic quality, amount of predictability or surprise, and how a model can be directed towards different output paths are essential. Training machine learning models for computer music is also a collaborative dialogue between the artist and the system, involving setting up algorithms to learn in ways that are both constrained and open-ended.
This research exposition concerns an approach to computer music that focuses on experimental uses of machine learning in algorithmic composition and live coding. Four approaches will be discussed, each questioning how machine learning can contribute to digital music creation. The different threads explore strategies for generating, manipulating, and interpreting musical material, training data, and learning models. The goal is to discover how such approaches can enable original artistic practices while demonstrating how they can generate something unique.
Central to the project is the idea of perceiving machine learning algorithms as operations that not only process data but also provide access to a different dimension of artistic exploration. This involves producing experimental workflows that combine algorithmic generation with the systematic treatment of musical material to develop compositional processes based on a training process that highlights a machine learning model exploration. Through these methods, the relationship between data gathering, learning processes, and algorithmic approaches is brought to the foreground, highlighting how questioning them can unlock generative potential.
Integrating sound, training, and code is a fundamental part of the project, and developing machine learning systems is closely tied to compositional practice. The aim of addressing the interaction between algorithm design, system development, and creative output is to blur the boundaries between tool-making, musical creation, and research inquiry. Questioning the scepticism among musicians, as identified by Knotts and Collins (2020), the experimental attitudes discussed here are presented to challenge and refine these distinctions, offering insights into how machine learning can review the relationship between composition, coding, and research.
The text threads of this exposition are structured horizontally, each contributing to the overarching exploration. The current introduction outlines the core concerns and questions, providing a basis for the following sections. The next four threads explore speculative paths through technical projects, musical performances, and approaches to sound synthesis. While the sections are logically connected from left to right, alternative paths through the exposition are also possible. For instance, one might begin with a specific project or media section and work backwards to uncover the ideas presented.
Recently, much focus on music technology research has been on machine learning techniques such as deep learning and generative AI. The outcome of such approaches frequently concerns automatic music generation, style transfer and sound classification. These usually require large data sets for training and important computational requirements that take considerable time to complete. Once trained, AI models present vast spaces and many parameters to control, often without any provided context for operating such technology. Meanwhile, classic algorithmic composition techniques such as stochastic approaches, selection principles or agent-based systems bring about a rich tradition and practical knowledge while lacking adaptability and operational richness.
An essential goal of this research is to combine machine-learning approaches with established algorithmic composition processes. It seeks to critically examine the use of generative algorithms through interaction with machine learning models, and how the training and creating of data for machine learning can become a substantial part of that process.
The other main motivation behind this project came from my earlier research on sound analysis and database-driven composition using my custom database-drive SND Archive system (https://github.com/bjarnig/SNDArchive). This system was designed to analyse and store extensive collections of sounds, enabling them to be queried and recomposed in ways that revealed original aspects of the sound material. I developed a method that emphasised the exploration of the analysis data, using sound attributes like pitch, timbre, and loudness as the basis for compositional decisions. This approach allowed me to recontextualise personal recordings of the past by segmenting and analysing them to form new sonorities and control data.
The interaction between sound archives and algorithmic agents within the SND Archive offered a compositional model for using data-driven processes as a creative tool. The resulting compositions (available here: https://flagdayrecordings.bandcamp.com/album/upics) emerged not just from the material itself but also from the relationship between analysis, querying, and recombination. Using machine learning to derive further information from my data was a logical next step since I wanted to understand not only my sounds but also my creative tendencies and decision-making patterns.
Data Making
A machine learning process begins with some sort of data input or data ingestion, where “raw” data is gathered that will be used as a basis for later stages. The data can then be further manipulated, for example, through pre-processing, which might involve cleaning the data to remove inconsistencies and errors or transforming it into a usable format. With the prepared data, one usually proceeds to a training stage, where a chosen learning algorithm is applied to the selected data to train a predictive or analytical model. After training, the model undergoes analysis to evaluate its performance. This can be followed by feedback and iteration but also tuning, and comparing the model’s output against the training data. Finally, a refinement stage involves iterating on parameters, algorithms, or even the data itself to improve the model further and how it matches the given goals.
In this project, I question the data-gathering activities and understand them as a crucial part of my compositional work. The data I have used are purely derived from my artistic practice. They are made of different approaches to audio analysis, material choices, parametric states and selection processes. Data is not seen as something given but rather as something that emerges from the artistic works that employ them. Perhaps data is never truly ‘raw.’ Instead, it is more useful to consider how data must first be imagined in order to exist and function as such. As Gitelman (2013) states, “data need to be imagined as data to exist and function as such, and the imagination of data entails an interpretive base” (Gitelman 2013).
Data reading is also something to question and holds a binding but interesting relationship to the gathering of information since it comes at a later stage. A constructive view of those phases often involves an interpretation of data as dynamic, evolving or temporal, or, as emphasised by Gioti, Einbond and Born: “an understanding of data as process: as something that is made (and therefore artificial), situated, and contingent on material conditions, rather than “a priori and collectible” (Gioti, Einbond, Born 2022). Just as compositional and performance practices are shaped by artistic intentions, data-gathering processes should be designed to reflect the artistic aims and attitudes from which they emerge.
A recurring question I faced during the data-gathering process was related to what I wanted to model. I quickly understood that arriving at an average (or general) representation of my work was unlikely to provide much interest. When working out the research, I observed how little attention is usually put to the data collection approaches in most musical machine learning projects; for example, as noted by Morreale, Sharma, and Wei, “the lack of interest in how datasets are constructed can indeed be found in the lack of guidance in typical ML textbooks or syllabi” (Morreale, Sharma, Wei 2023). Instead, artistic interest is frequently motivated by something specific, unexpected or even accidental rather than something general or universal.
Standard data collection procedures, such as normalization and data cleaning, can have opposite effects, both enhancing clarity and structure while also removing irregularities that might hold artistic value. Poirier observes that “attempts to standardize data for comparability often erase local nuances, creating insights that simultaneously obscure specific contextual issues” (Poirier 2021). Since my focus here is to uncover and understand differently my practice and musical attitudes, speculative data gathering has become an essential field for experimentation. This involves many oddities and highlighting of data details that could easily have been ignored in the process and data-making pipelines but will influence the subsequent stages of the creative process.
Live Coding Partnership
Ever-Present Change has been performed twice. First, in April 2024, at the Conservatoriumzaal of Amare, and later, in October 2024, at the ToListenTo festival in Turin. Both performances explored live coding and reactive processes that responded to the sound analysis. During the first performance, no code was projected, while the second time, there was a projector showing the code typed during the performance. In the first instance, the reactive textures came about as triggered conditions, while during the second performance, the trained classification was used to provide responses. In both cases, the music emerges not solely from my intentions or the machine’s reply but from the interaction between the two. This partnership introduces a bidirectional influence, where the system actively contributes to the unfolding of events rather than merely serving as an instrument of human action or perception.
The live coding always starts from an empty page, where adding new code and refinement of parameters gradually shapes the sound. I use snippets to insert blocks of code. To a certain extent, the music already exists in the snippet collections that have been collected during the synthesis phase. As I proceed through the sound construction, the synthetic sound is analysed, and new sounds (that I have not necessarily chosen) are added and, in turn, start to influence my live coding.
Instead of following a predictable loop of action and reaction, both I and the reactive sounds change and evolve as this partnership unfolds. This exchange challenges a traditional call-and-response loop because both parties adapt. Here, composition and performance merge as a more continuous change, where the generative process is as much an entity in flux as the sound it produces.
Static Synthesis
Developed as an experiment in dynamically evolving sonorities, the composition Ever-Present Change merges live-coded sound with generative processes. This relation forms a piece that evolves through continuous interaction between algorithmic activity and manual intervention. Rather than presenting collections of successive sounds, the work delves into their formative principles, emphasising how sounds develop relationships through the technical processes that shape them. The order of events emerges from an observation process that responds to synthetic sound sources and questions how we attribute order and control. Through the observation process, the piece not only comments on its formation but also invites us to engage with the unfolding relationships that give rise to a sense of causality and structure
The title refers to ideas from process thinking that concern phenomena that represent an ever-present change. The idea is to bring about sounds that appear to be very static while at the same time constantly changing internally. I started the piece by synthesising a collection of sounds that conform to this vision of ever-presently changing sonorities. All of these are made through short and compact snippets in the SuperCollider programming language. The collection became quite large and the idea with the piece was to explore a succession of these sonorities. The piece contains no transitions, movements, or development of the presented material. Blocks of sounds are simply introduced and then followed by other blocks that contrast or complement previously introduced material. Since the artistic vision they are based on is a common thread, the succession process is intended to reveal more aspects of the sound gradually. In addition to the successive sounds, an observation process analyses the ongoing activity and introduces additional layered material.
The music is mostly relational in the sense that any notion of ‘sections’ or ‘transitions’ is caused by the properties and details of the synthetic sounds. All source processes are defined in relation to other parts, resulting in a ‘material network’ or ‘sound configuration’ that could be activated differently. Thinking relationally and bottom-up also allows the musical structure to be considered a network with different points and connections that spread without any single point of failure. The creative work then involves making new material, introducing it and following the ongoing process. The observation process was first created through triggers, so when the analysis reached a predefined condition, it would trigger suitable responses. In a later stage, the triggers were replaced with a classification algorithm that was trained on different sounds during the preparation phase.
The machine learning was made using the Flucom, (https://www.flucoma.org/) Classification module and makes a mapping between the output of an MFCC analysis and a set of predefined actions. The sound material used as input is often dense and with a broad spectral range that actually results in a certain unpredictability of the mapping. Additionally, I experimented with various effects during training that accounted for further twists. I also implemented an algorithm that I trigger during the live coding and can treat the mapping in various ways. For example, by deciding the duration of an MFCC period, the speed of selection actions and more.
Beyond Intent
In machine learning, classification refers to training an algorithm to predict the category or class to which an input belongs. Input data is provided alongside labelled outputs to train a classifier, allowing the model to learn associations and predict the most likely class for new inputs. This process is a form of supervised learning where the model iteratively adjusts to improve accuracy in predicting labels. Neural networks are commonly used for this purpose. For this particular piece, I used the MLPClassifier from the FluCoMA toolkit (https://flucoma.org/). Using classification allows the setting up of a fixed set of output for varying inputs and, therefore, reduces the mapping of what is learned during the training phase to a fixed set. It is often employed when “encoding an explicit logic of decision-making functions very poorly” (Burrell 2016). I decided to use a branching strategy that would be trained to map the input to six possible branches that would be activated.
For the training samples, I set myself to gather at least ten times the number of features per class, which for 13 MFCC values and six classes means at least 780 samples (13 * 6 * k). The training would be done through studio sessions where I had a small controller with knobs. As I executed the live coding process, I would take snapshots of the state of the analysis with a short windowing function. I first tried to devise categories of sounds that I would pre-imagine. For example, ‘sparse texture’, ‘low drone’, ‘pointillistic’ etc. However, such categories confused me as I went along; the boundaries were not always clear, and the labelling required a mental lookup at each step that did not put me at ease. Therefore, I shifted my approach, by simply using a range of six densities from spare to very dense. I still used the six possible classes, but reducing the range to a conceptually clear nominator made the whole process much more fluid. I executed several training sessions and finally chose the second one I did, simply based on intuition. It contained just over 800 samples.
I wanted the piece and live processes to embrace unpredictability, allowing my algorithms and processes to develop differently each time they would be played. The branching idea was extended by not having the six output classes correspond to some static reply but rather activate a “certain direction”. So, rather than producing fixed outcomes, the algorithm triggered the classification branches off in response to external inputs, internal behaviours, and programmed inputs, such as random number generators. In fact, the output classes became algorithms that are turned on. They can, for example, play a sequence of sounds or spectrally freeze the current input. In this way, the classification system is exerting its agency and shaping the musical context in ways that often go beyond my original intentions.
The ‘liveness’ of the system is a key element, as the ongoing execution of operations during a performance produces new and somehow unexpected sonic results. For both the live performance and the recorded video, I triggered the classification process manually. While the audio analysis runs without stopping, it only maps the sound I’m playing to one of the six output branches when explicitly activated.
To avoid a fixed, one-to-one kind of response, I introduced a time delay for certain parts so that the response effect becomes more gradual and slow. In this sense, the piece orients itself toward a solution space defined by the interaction between rapid, direct actions and slower, accumulative processes. This dual mode of response—fast, transient reactions and sustained, gradual responses—establishes the response cycle and structural grounds of the piece. The live partnership and duality created by the different temporalities mirror cognitive processes: fast, intuitive reactions to immediate sonic changes coexist with a slower, adaptive layer that integrates past sounds into present decisions.
Ever-Present Change is an ongoing negotiation between immediacy and memory. Each performance is not a recreation but an unfolding process, where present actions shape future decisions, a dialogue between fast shifts and slow transformations.
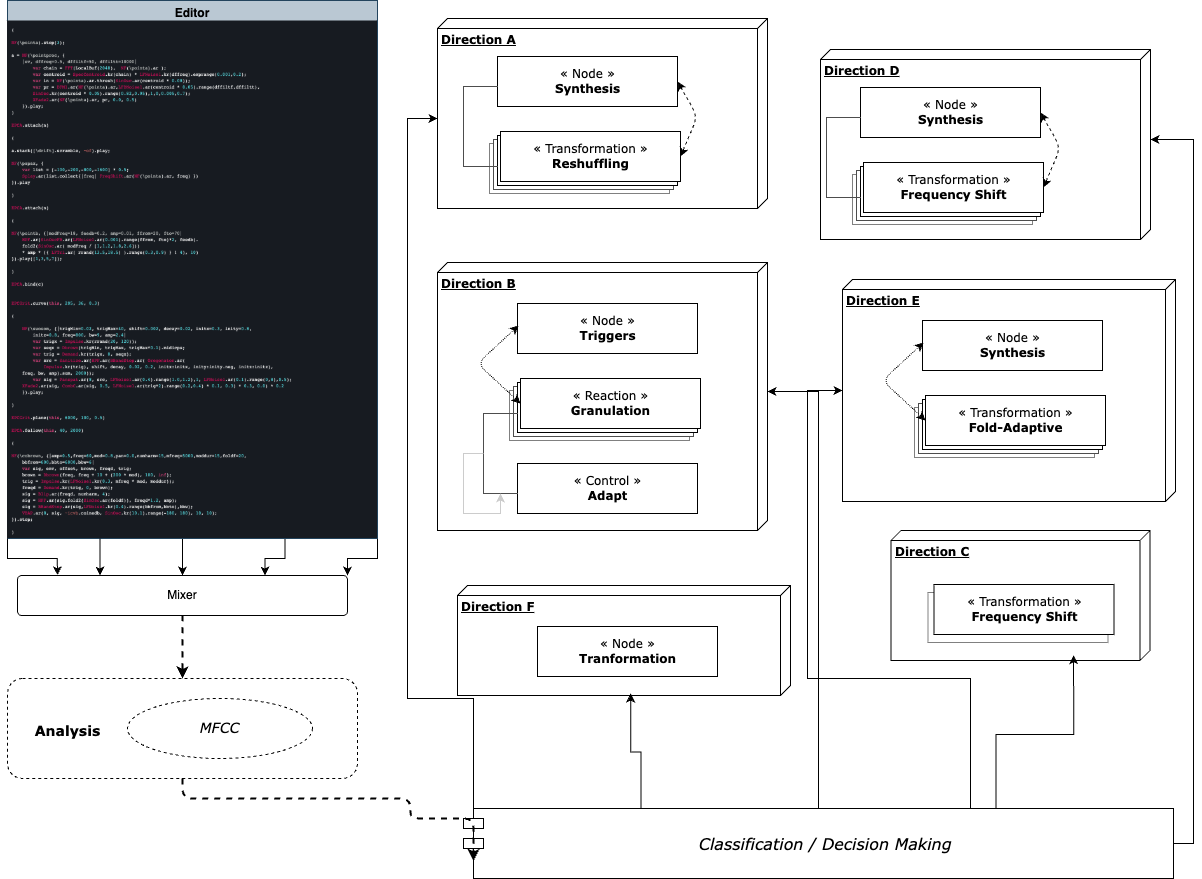

Evolving Networks
The experience of working with the EPC model as described above led to attempts to exploit further the idea of having sound itself interfacing with a machine learning model. Conceived as an experiment for dynamically navigating networks as a response to an incoming audio stream, ‘Streamlines’ was created as a software, piece and performance created using SuperCollider, the Keras API and P5.js. The piece is based on an inference process that has been trained using synthetic sound sources mapped to custom data structures that are designed to appear as nodes in a network. During a performance, a stream of live-coded sonorities is produced that is analysed and then used to make predictions of suitable nodes. These nodes then form part of a dynamically growing network of short, articulated sequences that form a counterpart to the synthetic sound. ‘Streamlines’ runs in a web browser where the visual outcomes of the simulations are displayed. The piece reconsiders the relationship between generative activity using the learning and inference processes, which are subsequently ‘interpreted’ by sound processes in SuperCollider, creating feedback regarding causes and interaction.
Running the inference process while growing the network became the carrier of musical development. The interaction enforces a way of thinking that revolves around the dynamic building of graphs and sonic behaviours. An attitude that considers musical output as something that emerges from an interaction with a trained machine-learning model. The idea is that evolving processes are set in motion where the trained mappings influence a live-coding activity and where the creator/composer becomes an active observer of the network growth and inference. The output can only sometimes be controlled in detail but is instead interpreted and further processed. Live-coded synthesis as a mode of composition is what drives the possible outputs of ‘Streamlines’. The observer (live-coder) produces computer-generated sound where interaction emerges through the inference of the analysis and the treatment of the growing network.
Besides the live-coded synthesis and building of networks, two other essential modes of control are employed. Configuring the context (initial states) and interfering (or blocking) the generated output. For all of the interaction modes, both manual commands and audio-driven operations can be used. This way of working introduces an operational space within which highly detailed synthesis interacts and clashes with generators of computational behaviours. ‘Streamlines’ was intended to question the concepts of generative activity, learning, inference, and network growth through an ongoing reconfiguration and live coding.
Beautiful Strategies
Streamlines premiered in September 2024 for the opening event of The Conference on AI and Music Creativity (AIMC) 2024, held at The University of Oxford. In addition to the sound-to-network mapping, I decided to emphasise further how the network of nodes is explored by creating a visualisation that would form part of the performance. The visual component will start by plotting all the possible points in the network. Then, as the performance occurs, a mapping is executed, resulting in a specific path through the network. This is highlighted through different colouring so that the audience should get a feeling for how, at each mapping moment, a different path through the network of all possibilities is chosen to play and visualise. The path does, again, not represent something totally fixed, as described above.
Furthermore, a choice was made to introduce an algorithmic aspect of how and when to interpret the learned path. For the EPC model, every interaction with sound-to-event mapping was made manually and as part of the performance. For Streamlines, no such evocations are possible. However, different algorithms are running that execute the mapping. For the live-coding performer, the decision is then to make how to interpret a mapping. For example, in the action library that accommodates the piece, a choice can be made of creating a mapping of ‘stress’ or ‘drifting’. Those algorithms will treat the possible nodes in a very different way. They will also activate the mapping differently. For example, instead of mapping frequently, or when a sound changes, it can also be interesting to map sparsely and not so often. These activation algorithms formed a crucial component of the piece.
In her book “Beautiful Data”, Orit Halpern notes how data visualisation contributes to a historical way of understanding data interpretations, where data and data exploration is, in fact, “ the site of exploration; generating in turn “strategies” that are also “beautiful.” (Halpern 2015). Her comments emphasise how the framing of a dataset can result in aesthetic implications but also how the strategies of exploration are of importance. On a similar note, my piece Streamlines represents a path through a larger space of data points that have been created before but where other avenues are certainly possible. Wanting to elaborate on the ‘strategies’ and exploration, I created a variation piece, ‘Striations’, which extends the original model while introducing a different network structure that is explored through sound. While retaining the core idea of mapping audio analysis to a dynamic network of sound events, there is a change in the learning algorithm; the input data was manipulated via an algorithm, the listening happens less frequently and over a different window and different synthesis are used to explore the model. By integrating those changes, the work examines how different learning architectures influence emergent outcomes and interactions, allowing for a deeper reflection on the relationship between algorithmic structures, sonic material, and performative concerns.
Interactive machine learning systems such as the ones made for Streamlines and Striations act as collaborative agents for composing music where the central consideration is the degree of agency within these systems and the orientation of their contributions—these contrast with systems driven by strict supervision that often mirror deterministic pathways. Should the agency of machine learning systems be understood in terms of their dependence on the input data or by their capacity for autonomous output? The Streamlines and Striations models are not only tools for achieving predetermined objectives but are instead extensions of something more exploratory and in progress. They develop their identity not solely through their training but through the decisions made during the performance when the different algorithms interpreting the data come into play. This shared agency points to the system’s role as a collaborator and a productive participant whose contributions are shaped by inference and manual intervention.
Sequential Learning
With Streamlines, I wanted to investigate how live sound could be used to navigate and interact with a pre-composed structure. In a way, this extended the EPC model, but rather than training audio to map to a limited set of branching options, the aim here was to use sound as a means to explore a dense network of pre-existing material and the relationships between its instances. To accomplish this, I implemented a Seq2Seq machine learning model using the Keras library, mapping an incoming MFCC-based audio analysis to a network of sound events. Each MFCC snapshot was paired with a corresponding network of sound events, forming the training data. The MFCC array consists of floating-point values, while the network of sound events is represented as a set of nodes, each identified by an ID and connected to other nodes via edges. The Seq2Seq algorithm emphasises the sequential nature of the vector string used to represent the nodes, meaning the “pre-composed” material is explored through the model.
To construct the dataset, I decided to rethink my training process. I started by working out the network by creating short sequences of different sound materials and algorithms to form links between them. Each path in the network would consist of a start position and then possible next nodes. In this manner, a subset of the network could be purely deterministic or involve chance as to how to choose the next nodes played once a previous one is completed. A subset of the network can be represented as a string that contains states and the possible following states. To review the training process, I decided to reverse the mapping direction. I would start with the destination instead of the source. To do so, I created simple algorithms that could explore different configurations of paths within the network. These could be triggered on demand. Once a configuration of interest was generated, I would turn to the synthesis and adapt existing material created for Streamlines to match the current network subset. This led to multiple snapshots of MFCC arrays and their corresponding sound event networks. The process was repeated many times to build a large dataset. To enhance the robustness of the model, I applied data augmentation by introducing variations to both the MFCC arrays and the sound event networks. Once the dataset was sufficiently populated, I used it to train the Keras-based Seq2Seq model. Finally, after completing the training process, the resulting model was stored for future inference and exploration.

Parametric Spaces
For both Ever-Present Change and Streamlines, sound analysis was used as a means to interact with a machine-learning model. Sound then became a tool for uncovering aspects of the learning process that had previously been overlooked. In a performance setting, this approach created a feedback cycle where the system’s agency and responsiveness shaped the evolving interaction; input sounds addressing the machine learning model, which in turn influenced the output. While these methods did produce interesting results, it also felt as if they had reached a limit and that this approach could not be developed further. For my following iteration, I decided to shift focus. Instead of using sound as input to the learning process, I turned to machine learning of parameters that actually produce sound. The choice was to focus on parametric controls and mappings that grouped synthesis processes into modularised generative units. These units, much like learning models, functioned as black boxes, each providing a multi-dimensional space of eight parameters ranging from 0.0 to 1.0.
Parametric spaces are shaped by the relationships established between input data and the resulting parameters. In a configuration space, the resulting intentions are not fully realised beforehand but come about during interaction with the system. Within the broader parametric space, Pluta identifies specific zones of compelling sound, calling them 'pockets of magic,' “the places where all of the parameters line up, and where subtle changes between parameters result in compelling sounds.” (Pluta 2021). By focusing on the parametric as “ongoing,” the aim was to explore conditions where one engages continuously with the evolving mappings between input data and sound synthesis. The iterative navigation of these spaces allows musical material to emerge not as a fixed output but as a dynamic response to changes in input or exploration within the parametric space itself. This process bridges the gap between the algorithmic generation of parameters and the compositional act of shaping musical outcomes. Once the configuration of different parametric spaces was obtained, algorithmic methods were used to generate sound states based, for example, on randomness and chaotic functions to create diverse parametric configurations. A snapshot approach to the data-making followed so a (familiar) feedback process could be executed where I would create a parametric configuration by running the algorithms to create plausible states and then store snapshots of those I liked. However, a taste-based approach to data-making did not fit the purpose of the current work. What seemed more promising to explore further, based on the previous project outputs, was learning from or with something that would be ongoing in parallel to any new sound generation.
After a few experimental tryouts, a generative model was developed to produce material that would form the counterpart to the parametric synthesis I was implementing. This model was an automated extension of the Streamlines program that would require no manual input. By automating some of the manual inputs and then submitting others to algorithmic variation processes, the mechanism could generate music that would somehow be related to Streamlines but also relatively different from it. The model was designed to operate in a more sparse manner, leaving plenty of space and gaps for the partnership actor. This new partnership would form the backbone of the data-making as I activated the parametric models to produce sound relating to the heavily modified Streamlines model. The snapshot approach was kept, which would be the only artefact stored since all the generated audio from the algorithmic version of Streamlines was omitted. Focusing on the actions and mappings within this parametric space puts sound composition as an interactive process in the foreground. The data gathering, therefore, would take place through this “collaboration”, and snapshots would be stored based on intuition but regularly and in large amounts.
Unknown Intentions
Assembling data for the approaches explored here is similar to an act of capturing snapshots; each data point is a frozen instance of an ongoing activity, a static representation of a process of a broader nature. The data-making process is, therefore, like a photographic session where one attempts to capture the subject from diverse angles to recreate a holistic image. Influenced by this attitude, I directed the learning processes chosen for Interstice towards image-based algorithms. This was also affected because many of the more interesting contemporary algorithms for deep learning and generative AI perform exceptionally well on image data. The approach I decided on would be to use the data points created for Interstice (described here above) but to record the audio output a parametric configuration produced. This audio would then be analysed as a spectrogram, and the pairing of the parametric configuration with the spectrogram image would be used as data for the next phase.
Having images to learn from allowed for a different approach than the mapping-based ones described above. The images allow me to experiment with two interesting learning approaches. The first would be to use the inference paradigm to essentially input a spectrogram-based representation of any given input sound to be mapped to a parametric snapshot of the modules I used for the learning process. The second would be to use a deep-learning process that, instead of working with a mapping-based regression, allows for unsupervised approaches such as a variational autoencoder. The system is inherently fluid, blurring the lines between instrument and process, design and execution.
Algorithms are often conceived as tools designed to fulfil predefined goals or solve specific problems. However, their role can extend far beyond such fixed purposes. The notion of intention within algorithmic processes does not always precede their application; instead, it can emerge dynamically as part of an iterative and exploratory creative process. Intention, then, becomes something to be discovered, evolving as algorithms interact with material and input. The variational autoencoder (VAE) is a machine learning algorithm that proceeds by encoding input data into a structured latent space, where representations are not mapped but continuously distributed across a lower-dimensional manifold. Unlike direct regression-based mappings, this approach does not attempt to learn explicit parameter correlations but instead learns to encode and reconstruct input data through probabilistic modelling. By defining a structured space of possibilities, the VAE allows for interpolation between learned representations and the generation of new configurations that do not explicitly exist within the training data. For Interstice, latent space exploration received more attention moving forward than image-to-parameter translation.
Using representations or parametrical spaces enabled by the variational autoencoder (VAE) can serve as tools for clarification and discovery, where the idea of developing and refining a learning approach becomes a goal of the compositional process. Alterations and iteration are essential, allowing systems to evolve alongside generative approaches. The concern, then, is to emphasise paths rather than endpoints. Wandering was used as a strategy, a method of selection, refinement, and retention, resulting in moments of significance. These moments are not predefined but are revealed through the act of exploration, guiding the process and giving structure to what might otherwise feel unbounded. In this way, selection becomes less about choosing an end goal and more about curating a journey of discovery, where each choice reflects a deeper interaction with the material itself.
Inferred Causality
The Interstice model performs well for exploring parametric spaces and converting sounds (and images) into parametric configurations based on inference. However, there is no given path from static states to music that evolves over time. The choice was made to explore three kinds of changes in time algorithmically. The first would concern movements within the latent space. This also poses problems since the reduced search space often proves to be “highly unstructured in relation to aesthetic concerns” (McCormack 2020). These could be gradual or stepwise and performed on defined subsets of the latent vectors. The second approach would concern interpolations between a set of parametric states. Given a set of two or more states of parameters, an interpolation can be executed that moves from one to the other. The movements can happen over defined curves, proceed in jumps or neglect a parametric change for specific parameters. Finally, the third way of introducing change would be to algorithmically variate, deviate, or modulate parameters based on different algorithms, leading to other treatments for different parameter sets. The synthesis modules could then be connected to a cause of change and, by doing so, make music happen over time. The algorithm, therefore, enters in dialogue with the parameter snapshots obtained from the machine learning, but only as a point of departure.
In practice, the modules have been connected together where the introduced changes can be applied during the sound creation process or live performance. When doing so, relationships are established where changes in one entity can affect the behaviour of another or trigger operations executed by a third, forming a network of interactions within a complex system. In an algorithmic machine learning context, where decisions are influenced by layers of abstraction, historical data, and real-time inputs, the notion of causality becomes even more elusive. Circular causality can emerge through feedback loops between the human operator and the system, where the machine’s outputs influence the operator’s decisions, and those decisions, in turn, modify the machine’s behaviour. In such a dynamic environment, reciprocal observation between the algorithm and myself can make it increasingly challenging to determine which entity is responsible for any specific sequence of actions.
Real-time generative and machine learning systems, operating through intricate patterns of inference and adaptation, often blur the distinction between cause and effect. Outputs may not correspond to singular inputs but to an interplay of past training, learned associations, and momentary adjustments. The one operating these systems, interpreting these outputs, further feeds into the loop, creating a shared agency where causality is somehow distributed and diffused. The work produced through the Interstice model introduced a different aspect than the others since it operates on parameters instead of sound properties. This allowed for a more free attitude that, ultimately, allowed for a more dynamic musical output that introduced different musical aspects and sound forms.

Aesthetic Evaluation
In the projects discussed above, a significant focus has been put on an evaluation feedback loop that persists throughout the works. This evaluation process takes place, for example, through the classification branches of EPC, the network paths of Streamlines or the parametric configuration of Interstice. For all of them, an assessment is required by a human or machine of musical material. The outcome is then interpreted and executed in relation to the inputs and learning data. Such a focus on aesthetic measurement is something highlighted by the partnership models frequently encountered in musical machine learning and sound assessment. How should we evaluate our contribution or the one originating from a partnership-based algorithm? How should we think of the following interactive responses, and when should these be evaluated based on aesthetic criteria?
In her insightful work Bias for Bass Clarinet and Interactive Music System, composer Artemi-Maria Gioti questions AI bias and computational aesthetic evaluation. A central theme in her work is whether and how computers can make aesthetically informed decisions. This inquiry extends beyond technical implementation, reaching into broader issues regarding the nature of aesthetic judgment itself. Bias explicitly operates within a paradigm where subjectivity is central. Gioti trains neural networks on aesthetic judgments that she has made, reinforcing the personal and fluctuating nature of aesthetic evaluation. Rather than aiming for consistency or accuracy, she embraces the instability of aesthetic preference, allowing a system to develop its own exaggerated biases that, for example, favour “low frequency sounds over high frequency ones and static, drone-like textures consisting of sustained sounds over fast and virtuosic melodic passages.” (Gioti 2021). Furthermore, her system’s ability to “lose interest” in particular sounds and “redirect” the musician’s focus illustrates how machine agency can exert influence that directly relates to an aesthetic response to sonic activity.
As part of this research project, Artemi-Maria generously accepted to serve as a mentor and provide input and feedback on some of my work covered here. Her feedback emphasised many relevant aspects and points I had not considered. For example, how I need to highlight the interactive and adaptive nature of my work rather than focusing solely on the final sound results. She advised me to make the dialogue between me and the system more explicit, such as how it responds, how it challenges me, how this interaction shapes my practice, etc. It was also suggested that I amplify the partnership by acoustically separating the sources and highlighting the interactivity through the sound itself. She then encouraged me to consider what such interaction adds to my practice, particularly regarding the challenges it introduces and how it might expand or redefine my approaches to live coding. Her input also made me question my internal feedback cycles since the process, so far, had been to implement an idea, execute the musical results and, based on learning/feedback/understanding, change the approach for the next iteration. However, questioning what had already been completed was secondary.
A critical feedback point was raised about taking more significant risks in the whole process and balancing intention with what actually happens in practice. The relationship between real-time and offline processing was also questioned as to how this could be made more part of the artistic output. Another significant theme in the feedback was the role of aesthetic judgment. There was a suggestion to explore the tension between capturing and defining aesthetic choices versus allowing for unpredictability and risk, which connects to a broader challenge of mine, the teasing out of the motivations behind my work and identifying what truly drives my practice, always a complex but essential responsibility.
Neural Synthesis
During the initial phases of this project, I experimented with machine learning approaches such as WaveNet, SampleRNN, and, in particular, IRCAM’s RAVE. RAVE is a neural audio synthesis model based on a variational autoencoder designed for real-time sound generation and transformation. It compresses raw waveforms into a latent space representation, allowing for smooth interpolation, resynthesis, and expressive timbral manipulations. See more information here: https://forum.ircam.fr/projects/detail/rave/
However, I quickly became discouraged by how difficult RAVE was to grasp and control fully. The model’s latent space, while interesting, often felt abstract and unpredictable. Coming from a sound practice where precise control is kept of every variable in the process, the latent space offered by a trained RAVE model feels as if the sound control has somehow been imposed where the task is reduced to simply exploring that output. The interactive element that had proven fruitful in the previous models is harder to establish. Additionally, there are quite excessive training times required, with the first training phase lasting for about three or four days and the second phase taking anywhere from four days to three weeks. This proved impractical for rapid experimentation and iteration. Put off by these limitations and moved away from the model, I decided to pause my work with RAVE and returned only once the aesthetic evaluation topics emerged as significant.
A particularly interesting aspect of the neural waveforms of RAVE is is the (possibility of) exploration of the cross-synthesis feature space that is based on latent space transformations, where audio is encoded to RAVE latent space, allowing, therefore, one sound to explore another. The outcome usually preserves the original temporal structure (phrasing, envelope, dynamics) while reshaping the timbre and texture to fit the incoming sound. RAVE recommending at least an hour of input sounds, I freely composed 60 one-minute sound files aimed to explore the sonorities the project had been moving towards. I then created trained RAVE models by running the learning process on a rented by-hour server in Frankfurt. Different approaches also followed, for example, training on the variation of the files and spectral transformations of the files, which resulted in a few different model versions to explore. However, the excessive training times did strongly restrict what could be done for obvious temporal, financial and even environmental concerns.
Machine learning systems in algorithmic music often operate as black boxes where the internal workings are either inaccessible or too complex to understand. These systems then expose their functionality through inputs and outputs, where the inner functionality remains a mystery. The process is abstracted away, leaving the interaction at the surface level. However, this also introduces an interesting dimension to the idea of a learning process since one adapts to the exploring black box, and knowledge is created by exploring the relationships between trying different inputs and evaluating the corresponding outputs. Contrary to many recent currents in Computer Music, such as adaptive systems or feedback processes, the machine learning models remain static after training; their internal structures do not evolve during real-time use, limiting interaction and something like a learning process that assumes things change over time.
For the last piece discussed here, Wither (2025), the choice was made to take advantage of the black box-based interaction and model exploring via input. Using the trained RAVE models, I set up a system that would load them in several ways in addition to rules that would be attached, such as pre and post-processing of the RAVE input sounds. I also added a few adaptive processes, long delays, feedback and audio analysis that would influence the network based on the sound that was coming in. Through live coding and synthetic sounds, I would then explore the combined space of the RAVE models, their configuration and the attached rule-based system.
Of interest regarding Wither is how the limited control shapes how the input is designed. It introduces a tension between control and autonomy and a different perspective of the pre-composed and performed. The input sound material that was used was sparse and pointillistic.
References
Art in the age of machine learning. (2021). MIT Press. https://doi.org/10.7551/mitpress/12832.001.0001 (Audry, S. - Inferred Author)
Bown, O. (2021). Beyond the creative species: Making machines that make art and music. MIT Press.
Burrell, J. (2016). How the machine ‘thinks’: Understanding opacity in machine learning algorithms. Big Data & Society, 3(1). https://doi.org/10.1177/2053951715622512
Caillon, A., & Esling, P. (2022). RAVE: A variational autoencoder for fast and high-quality neural audio synthesis. IRCAM - Sorbonne Université. CNRS.
Döbereiner, L., & Pirrò, D. (2024). Speculative machine learning in sound synthesis. Proceedings from Sound and Music Computing Conference 2024 in Porto.
Drucker, J. (2009). SpecLab: Digital aesthetics and projects in speculative computing. University of Chicago Press.
Esling, P., & Chemla–Romeu-Santos, A. (2022). Challenges in creative generative models for music: A divergence maximization perspective. arXiv. https://arxiv.org/abs/2211.08856
Foster, D. (2023). Generative deep learning: Teaching machines to paint, write, compose, and play (2nd ed.). O'Reilly.
Gioti, A.-M. (2021). A compositional exploration of computational aesthetic evaluation and AI bias. https://doi.org/10.21428/92fbeb44.de74b046
Gioti, A.-M., Einbond, A., & Born, G. (2022). Composing the assemblage: Probing aesthetic and technical dimensions of artistic creation with machine learning. Computer Music Journal, 46(4), 62–80. https://doi.org/10.1162/comj_a_00658
Gitelman, L. (Ed.). (2013). “Raw data” is an oxymoron (Infrastructures series). MIT Press. http://mitpress-ebooks.mit.edu/product/raw-data-oxymoron
Halpern, O. (2004). Beautiful data: A history of vision and reason since 1945. Duke University Press. https://doi.org/10.2307/j.ctv1198xtq
Knotts, S., & Collings, N. (2020). A survey on the uptake of Music AI Software. Proceedings of the International Conference on New Interfaces for Musical Expression.
McCormack, J., & Lomas, A. (2021). Deep learning of individual aesthetics. Neural Computing and Applications, 33, 1–15. https://doi.org/10.1007/s00521-020-05376-7
Morreale, F., Sharma, M., & Wei, I.-C. (2023). Data collection in music generation training sets: A critical analysis. ISMIR 2023 Proceedings. https://researchspace.auckland.ac.nz/handle/2292/65322
Pluta, S. (2021). Multi-mapped Neural Networks for Control of High Dimensional Synthesis Systems.
Poirier, L. (2021). Reading datasets: Strategies for interpreting the politics of data signification. Big Data & Society, 8(2). https://doi.org/10.1177/20539517211029322
Conclusions
This research has examined the intersections of machine learning, algorithmic composition, and sound synthesis, demonstrating how generative models, interactive data processes, and real-time computational systems can challenge the notions of control, authorship, and agency in computer music. Machine learning in music raises concerns about control over generative systems. Algorithmic composition offers direct access to rule-based manipulation, whereas trained models present opaque decision-making structures. The experimental frameworks developed here suggest that machine learning should not merely be an “optimization tool” but a mechanism for problem-posing, exploring unpredictability, and challenging liveness.
A key finding of this research is that data-making is not a passive or neutral process. Rather than treating data as pre-existing raw material, this project engaged in data fabrication, wherein the training process itself was recursively informed by artistic intuition, performative feedback, and speculative processes. This approach problematises the machine learning paradigm that presumes large, curated datasets derived from external sources. Instead, it argues for data creation as an integral part of composition. One recurring issue encountered in the project is the static nature of trained models—once a model is built, it does not evolve in response to new data. This creates a disconnect between real-time performance and pre-trained behaviours. Machine learning infrastructure often remains inherently closed, whereas traditional live coding and algorithmic techniques allow for more adaptation. This suggests that future machine learning systems for music should move beyond static models toward architectures that integrate real-time adaptation.
Throughout this project, aesthetic evaluation emerged as a complex challenge. Drawing from critiques of aesthetic bias in AI (Gioti, 2021), the research reveals that machine learning models often reinforce preconceived notions of value, limiting their capacity for genuine innovation. By foregrounding iterative experimentation, feedback loops, and system responsiveness, this research proposes that machine learning should not aim to replicate existing aesthetic judgments but instead function as an apparatus for probing and expanding possibilities. The final and most significant conclusion is that machine learning should not be viewed as a problem-solving technology in music but as a tool for creative exploration, a means to pose new compositional questions rather than generate optimised results. Live coding and sound synthesis are foundational methodologies for exploring machine learning models in all the projects, suggesting that the relationship between composition and machine learning is not about new tools but an invitation to rethink composition as a process of interaction, exploratory action, and negotiated control.