Performing live electronic music comes with a number of challenges. It often involves various equipment; instruments, electronic devices, a laptop, as well as other performers. One carefully sets up the gear on stage, and begins to sound-check. The composed music starts to resonate throughout the hall and one tries to tune their sounds, adapting their composition to the concert space through the loudspeakers. The amount of, and arrangement of the loudspeakers are a crucial element to plan ahead for. Each sound system is set up in different configurations, depending mostly on the shape and size of the concert hall. Information regarding the concert space is usually shared before the day of the performance, but it is not possible to have any information on how uniquely textural sounds will react within that space. Often the performer is located on stage, where the full range of sound does not fully reach. The sound is normally being processed by a sound engineer who quite frequently is unfamiliar with the music. The kind of music and the sounds involved cannot be fully described or generalized simply, and most performers and composers who have presented electronic pieces of music live in a concert hall with multi-channel speakers will empathize with this feeling of insecurity, on top of their responsibilities to technical management. When composing live electronic music, an emphasis is placed on finding meaning between sounds and their relationship with the composed space through spatial movement and localization, produced using a variety of instruments, creating cohesion in the musical piece. These carefully designed and mastered pieces of music then fall into this very problem of dealing with sound in physical space, because every sound resonates differently, depending on where in the space they are heard, and the composed spatial images could vary from venue to venue depending on the shape of the concert hall and how the speaker arrays are set up.
The characteristics of the acoustics of the concert hall is one of the elements that influences how the sounds are heard. The location of the audience and the stage is another factor too. No matter how the spatialization of sounds is designed, there are places where spatial music cannot be perceived by every audience member as desired. Generally, experience from performing in different locations can guide the arrangement of a piece. Then it becomes a question of how far the composer should consider every detail of the spatialization of a sound, as very often one spends enormous amounts of time generating the ‘precise’ movement and localization of a sound, and carefully designs how that particular sound moves within a piece of music.
It is also true that often such uncertainty becomes a nice surprise. The concert space can help the composition to shine, to resonate with itself, and to even reveal undiscovered areas of sonic exploration.
A clear fact is that there is always/often uncertainty regarding the spatial experience of sound in the performance space. When this becomes a problem that the piece has to be re-adjusted to the space, there is no simple, global solution. However, could this unpredictability be taken as a musical premise? Could it be the inception of a musical piece that embraces the obstacles where the unknown factors of a space are central for a piece of music to be presented and heard uniquely? This research begins with such questions, where this ambiguity can be a creative resource. Sound spatializations can still be a core element to be explored in a music piece, but the unknown acoustic conditions of a performing space is welcomed.

One approach can be found in Audible Ecosystemics by Agostino Di Scipio[2], an auto-organized system. He uses 'circular causality’[3] where the sound originates by being picked up from a microphone, going through an adaptive DSP system, and coming out of loudspeakers after being transformed. (Figure 1) In regard to the transformation, he talks about composing ‘interactions’.
“A kind of self-organization is thus achieved […]. Here, ‘interaction’ is a structural element for something like a ‘system’ to emerge […]. System interactions, then, would be only indirectly implemented, the by-products of carefully planned-out interdependencies among system components[…]. This is a substantial move from interactive music composing to composing musical interactions, and perhaps more precisely it should be described as a shift from creating wanted sounds via interactive means, towards creating wanted interactions having audible traces.”[4]
The DSP system is not only an important element for sounds to be transformed, but it is created as the interface for sound to interact with itself by moving in the air, and by moving inside the system. ‘Having audible traces’ is also a fascinating point, in that the interaction leaves something behind. The circular causality has steps; from a sound created by a human agent to the DSP system, where there are routes that sound can travel, and to the sonic environment again, in order to enter to another step. The transformations therefore are made in multiple sequences.
Being inspired by the idea of creating internal and external interactions between the space, the human agent, and the designed system, the core idea of circular causality is applied in my system. However, some adaptations are necessary to be able to commit to the original intent of the project, where the performance and the actions of the performer play an important role, rather than an automated, space/system-only dependent operation. The ‘human-agent’ has to have more of an emphasis than is the case in Di Scipio’s work. Additionally, in Di Scipio, circular causality relies very much on variables in the DSP system, the control signals created by processing sonic data extracted from the ambience, including amplitude, density of events, and spectral properties[5]. Those variables are the keys for his system to organize the incoming sound in real-time. In order to give a role to the spatial gesture for the piece to evolve, the variables are dismissed in my system. Instead, I use a ‘pre-organized’ system where the paths of the sounds are already decided. I call it the ‘Controlled-Ecosystemics.’ The differences in the resulting sound rely more on the different origin of the sound feeding-back, that is shaped and driven by the spatial gesture of the sound and the characteristics of the shape of the space, the movement of the performer, and the signal processing of sounds. (Figure 2a, 2b)

Between listening and gestures
The Controlled Ecosystemics requires two microphones attached to the wrists of the performer. Those microphones act as the ‘moving ears’ that listen to the sound around the performer's location. Then there are the actual ears of the performer that have the role of perceptual analysis, each and every moment. It shares the role of computers in the Audible Ecosystemics of Di Scipio, in that machine listening analyses are happening in order to give a cue to what happens next. However, in the Controlled Ecosystemics the performer changes the location of the ears by changing the relative angles and distance of the hands. In a way, this can be seen as a gesture that controls the system. However, I would rather see it as an intuitive reaction to the sound traveling around the performer. The listening process is the key for the entire sonic development, by being informed by the physical involvement and therefore by triggering a physical reaction. The microphone picks up air pressure waves which are, for the most part, generated by the vibrations of the loudspeaker diaphragms. To achieve an alteration in these vibrations related solely to the interaction between performer, microphones, and loudspeakers, the distance between microphone and loudspeaker is changed[6]. The air pressure that moves around the performer is detectable enough, and it invokes a rather tiny movement of the hand to be able to change the pitch of the feedback sound, even at a significant level. The small change in the gesture where the virtual ears are located causes changes to the feedback sound, which is essential to the development of the piece. However, the change is not only dictated by the performer’s movement here, but also by the spatialization of the feedback sound that is also moving throughout the space and works in tandem with the performer’s motion. Eventually, there is not a single unit that acts as the controller. Rather, the acoustics of the performance space provides a platform for the interaction between the moving sounds and hands, and the computer processing shapes the incoming sound and enables it to evolve over time.
The position of the performer can be flexible, as long as the performer is located within the speaker dispersion zones and is able to pick up the sounds coming from any loudspeakers. More interestingly, such a setup invites exploring the differences in positions of the performer, the size and shape of different halls, and the multichannel setups. Therefore it opens up the possibilities for the audience in different positions as well, ideally surrounding the performer close by. In that way the listening experience can be more transparent, and they can be involved more deeply in the evolvement of sounds. In order to experiment with different setups and locations, I have composed two different versions of compositions using mainly two different loudspeaker settings: Wave Field Synthesis(WFS) system and an 8 channel ring system.
Stabilized Audio feedback
Those gestures by the performer, the spatialization, and the signal processing are happening due to the circular causality that is enabled by audio feedback, which generally is an uninvited guest in a music performance. Audio feedback is an audio signal looping between the input signal from a microphone and the output signal from a loudspeaker. During the loop, a certain frequency is heard, which is determined not only by resonant frequencies in the microphone and loudspeakers, but also the acoustics of the room which influences the emission patterns of the microphone and loudspeakers, and the distance between them[7]. In concert situations where microphones and loudspeakers are used, those frequencies are the ones to be removed in order to prevent any undesirable audio feedback from happening. The ever-growing tone is removed when the level of the microphone, or of the loudspeaker is reduced, or their positions changed. In other words, generating audio feedback requires a certain level of volume of the inputs and outputs, and a certain relative position of them, which is an obstacle for the aim of the project. In order to utilize audio feedback, it is necessary to find a way for the sound to be generated without those restrictions, and safely heard. Above all, those growing frequencies are crucial for the resonances of the room to be heard and to become the main source of the entire piece’s flow. The sound should therefore stay at an audible level to be processed in real-time.
In order to make it stabilized, a compressor can be a solution as it reduces the volume of louder sounds. In order to create an audio feedback loop, the positions of microphones are placed within the range of the angle of sound emission of the loudspeakers, and even with the use of a compressor, it is necessary to carefully tune the loudness of the input and output signals, because when the compressor starts compressing the sound, the quality of the sound changes. I chose Normalizer in SuperCollider, the programming language used in the piece, for this process. (The function of Normalizer in SuperCollider is different from the peak normalization of an audio sample, but it normalizes the input amplitude to the given level.) The use of Normalizer makes it possible to create audio feedback without raising the loudness very high, as it amplifies quiet sound by raising the input amplitude to the target level. This way, the feedback sound can remain relatively quiet and stable over time.
There is another important difference between the general audio feedback situation and the one using the Normalizer. The microphone acts as an exciter for the audio feedback to resonate and loop between the microphone and loudspeaker. Yet this method also enables a complete silence to be the starting point. A resonant tone emerges from the silence. After that, the sound reacts to itself via the movement of the performer, the spatialization, and the reflections generated in the hall where the pitch of the tone starts changing.
WFS system
WFS system is a spatial audio renderer where virtual acoustic environments are simulated and synthesized using large numbers of loudspeakers[8]. The system enables one to locate sounds in and outside of a speaker array and to draw spatial trajectories for sounds to travel. I used the Game of Life WFS system in the Hague that has 192 loudspeakers in a 10 by 10 square meter setup (Figure 3). The system doesn’t have a conventional ‘channel’ where one audio track is routed to one loudspeaker. Rather, small loudspeakers work together in order to localize and move a sound source. For a fixed media piece, the amount of the sound sources is dependent on the capacity of the servers that determine the number of sound sources and their lengths and behaviours, but for a live electronic piece, the audio interface inputs of the system limit the number of sound inputs. The Game of Life system has 8 analogue audio inputs so that any piece has a limitation to the number of output channels from the performer’s audio interface. Nevertheless, the advantages of using the system remain: the accuracy and flexibility of static and moving sound sources, the feasibility of drawing trajectories in any contour and distance, the possibility of duplications of each input, and no listening “sweet spot” but rather, a large “sweet zone.”

Feedback and motions
At the first stage of the experiments, the focus was on the relationship between a moving sound and its influence on the feedback sound. The balance between three different movements was the important starting point. Firstly, the moving sources are omitted and only the performer’s gestures are applied (Media 1). The two sound inputs from the two microphones on both hands are then the moving elements, together with the natural reflections and refractions from the hall, which are not controllable. During these experiments, the system was temporarily located in a giant kitchen, an open space full of kitchen goods, and the sounds were fully resonating all around the space. The spatial movement was therefore happening rather naturally, even without the need of moving sources.

The second experiment was made with moving sources mixed with static sources, and the hand movements dismissed (Media 2). The difference from the previous experiment is noticeable: the change of the pitch was happening more frequently. The result gives two possible musical choices. When the spatial movement is crossing the speaker arrays at a regular tempo, the movement can be used as a rhythm generator. This implies that the spatial movement can be utilized as a musical element. Another possibility is simply to reduce the amount of moving sources, as well as its speed. This way there is room for the hand movement to join the interactions between the sound and the spatial movements.
Transformation of sound - modules and trees
The audio feedback sounds, when they are picked up from the microphones and heard back via loudspeakers, and start moving within the performing space, enter into the synths of signal processing. A synth represents a single sound producing unit in SuperCollider[9]. The synths are triggered in real-time by using Routine method, a scheduler in SuperCollider. I call each synth as a module, and the combinations of modules a tree. The concept of tree comes from the Node tree in SuperCollider: a Node means a synth or a group that contains a number of Nodes, a tree is the structure when more than one node and/or group are executed in sequence and appear below another one. The reason why I call it a module is the connectibility and interchangeability between the nodes in the pieces; they become modular. One module is a designed synth which includes one or more unit generators to process incoming audio signals. Each module has one or more input and output buses that enable the module to connect to other modules. The position of a module in a tree is decided in two ways: by the order of execution, and by asking them to be placed in a certain position using Class methods in SuperCollider (e.g. .head, .before, .after, and .tail). I made three different groups: input, processing, and spatialization groups.
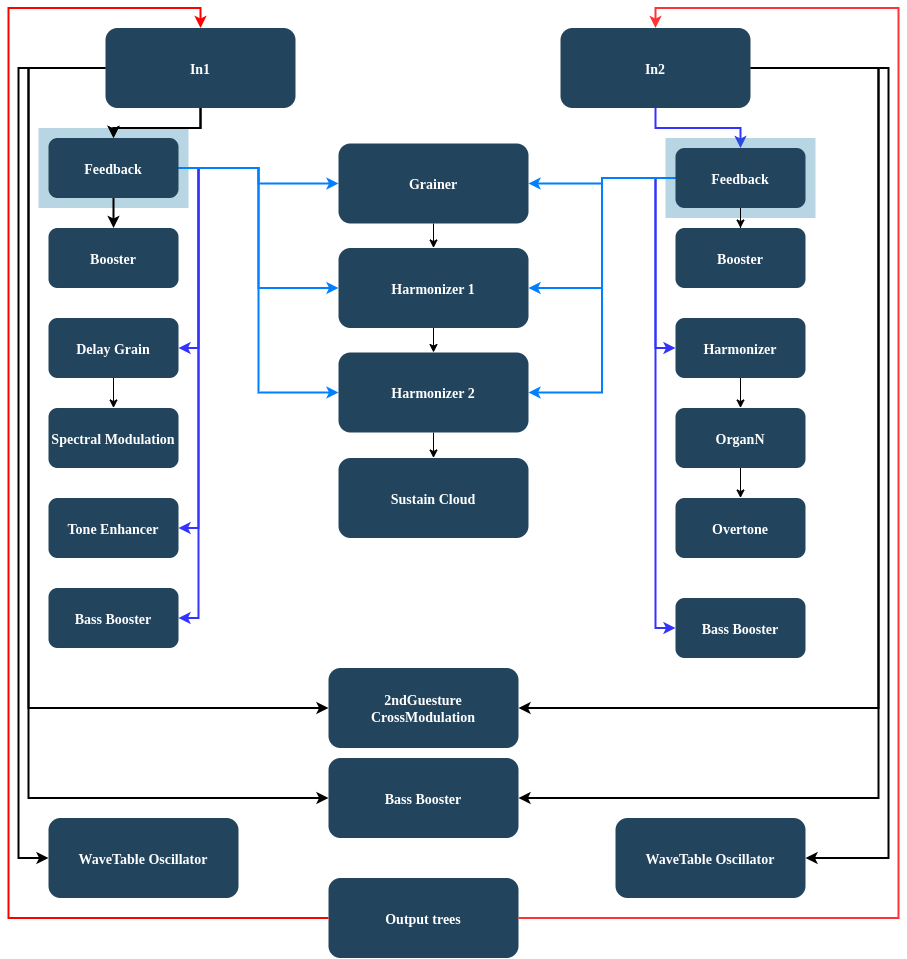
Those groups are comprised of different modules inside, and the entire group forms a tree. In Figure 4, the left side where Feedback/Spectrum modules are located, is the input group. The processing in the input group is chosen in order to first reveal the feedback sound, and then to expand its spectrum to create harmonic layers without destroying the central tone. The modules on the right are in the processing group that slowly distort and dismantle the harmonic structure coming from the first part. Each different microphone input has a tree in parallel, so the tree in Figure 4 indicates a half of the processing. Accordingly, they are treated separately, sometimes executed in different timings while the outcoming sounds are intermingled together in the space. This contributes to a more complicated interaction between the processed sounds of the two microphones.
The module colored in yellow receives the amplitude values of the direct input signal that is converted to a control signal for a pulse oscillator. This oscillator then creates a rhythmic pattern. Amplitudes of two different inputs are cross fed into each other, generating two different pulsations that I consider a second gesture. It can be seen as a modification to the development of the original tones, or as a companion that gives an extra supporting layer. Some of the modules here are disappearing over time, or returning in other positions. The tree is growing or shrinking. This way, the sound that flows is not static, but evolves over time. The outs at the bottom are in the spatialization groups that deliver all the incoming sound out to the space with their own unique movements and localizations. The limited number of outputs and the number of inputs in the WFS system, are duplicated in different layers. In this way, there are more than 8 positions and movements that are juxtaposed. The feedback module under ‘in1’ sends the stabilized feedback sound directly back to the input through ‘out1’, and the rest of the outputs are sometimes going through another module before they are coming out through the spatial modules.


Gestures and complexity - From tones to noise
As the trees are formed in time, the sound structure changes gradually. Therefore, it reaches a moment where the original feedback sound is not clearly heard anymore. What is heard, is rather a more complicated sound construction than a simple tone. It can be called ‘noise’ in comparison to the tone, which indicates a complexity of juxtapositions of sounds transformed, rather than a white noise. Di Scipio talks about noise in the Audible Ecosystemics as such,
“the role of noise is crucial […]. Noise is the medium itself where a sound-generating system is situated, strictly speaking, its ambience. In addition, noise is the energy supply by which a self-organizing system can maintain itself and develop”[10]
He draws the attention tothe two different roles of the noise in his system, which are applicable to my system as well. He starts with indicating the ambient noise embedded in the system, and then explains how the noise becomes a support for the system to develop. For the same reason, the tree structures are designed in order to reach a complexity where a more complicated sound organically grows over time. Then, this sound is picked up by microphones, played back via the speakers, and again into the air, continuing its circulation.
It is not only the modules and trees, but also the sound spatializations that go into complex movements. The slow, gentle movements at the beginning (Media 3) become more rapid and complex in its trajectories. The only element that is necessarily becoming simpler is the gesture of the hand, because the incoming signal is rather noisy so that changing the locations of two microphones does not impart much influence. Yet it is the moment of the hands that the performer uses rather intuitively and freely which express how the music flows at the moment.
Experiment with sensors

Figure 6. Arduino nano 33 BLE on a wrist
As the gestures of the hands are basically acting as two ears, there is room for mapping the hand gestures to spatial gestures. This idea leads me to experiment with sensors on the wrist, measuring speed of gestures, directions, and the distances between the hand and the ground using accelerometer, gyroscope, magnetometer sensors, and eventually to evaluate if those variables are useful in the piece. Arduino nano 33BLE (Figure 6) is chosen, which is small enough to attach on the wrist, and has all three sensors. The WFS system allows a user to connect a sensor via Bluetooth port, and receive an Open Sound Control (OSC) signal via WFSCollider, the software for the system.
The experiments are made on three different mappings: 1. drawing a spatial trajectory, 2. changing the speed of multiple, pre-designed spatial trajectories, and 3. a conditional decision-making tool in processing module trees.
- Drawing spatial trajectory is enabled by a gyroscope, which is measuring or maintaining orientation and angular velocity[11]. It provides x and y values, and those are directly mapped and draw a trajectory in real-time.
- Changing the speed of pre-designed trajectories is done by using an accelerometer, where the speed of the hand directly influences the speed of trajectories.
- Triggering modules is done by changing the direction of the hand rapidly, which is recognized by the gyroscope (Figure 7). A sudden change of direction from going up to going down can cause a trigger or exchange of modules.
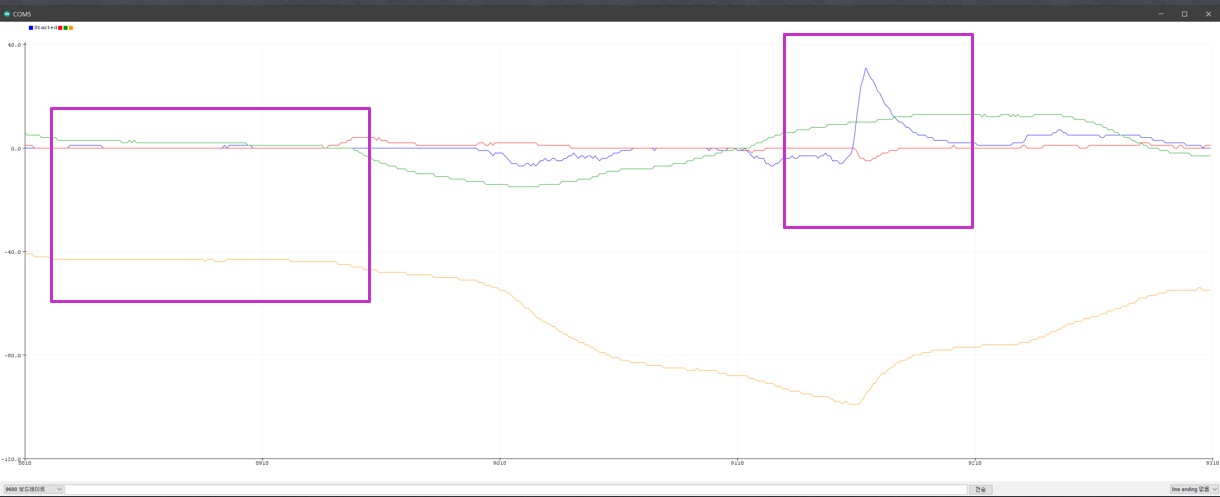
Figure 7. Example of the static moment of hand direction (the first square) and the moment of the direction change(the second square) in gyroscope
Those experiments are useful, first of all, to examine the possibilities of using sensors in generating spatial movements. A direct connection between the hand gesture and spatial gesture is applicable. However, the only possible application of the sensors within the context of this project is to use them to change the speed of the pre-designed trajectories, because it is useful for various movements to synchronize their speed in unison. The rest has to be dismissed because the hand gestures are already bound to controlling sound inputs. The attention cannot simply be placed in controlling several different, and important parameters at the same time, which are also the core ones to interact with each other. The performer cannot possibly keep the attention in balance. This means that the system already generates enough complexity from creating interactions between sound, spatialization, and hand gestures. Having another controlling element does not seem to be necessary at the current stage. Nevertheless, the experiments were useful for considerations of alternative ways of controlling spatial gestures, and offered a good demonstration of possible applications in future projects.
The two pieces share the basic sound source and the manner of creating development. The main differences are found in the spatialization methods, and the use of different shapes of modules and trees. It implies that the audio feedback sound created by the resonance of the space, two microphones, and loudspeakers goes through different paths, and therefore different results are encountered. In this chapter the methods shared with the WFS piece are not repeated.
8 channel sound system
An 8-channel system with a circular configuration is chosen because it can be regarded as one of the conventional multichannel setups. The 8 loudspeakers surround the audience, and ideally the performer is located in the center. However, in a concert place where there is a clear division between the stage and the seats for the audience, the performer often stays more to the front side of the speakers.

Figure 8. an octophonic system setup
Different from the WFS system, there is no single method and tool for creating a spatialization for the setup, and a very accurate, complicated trajectory is not as feasible as in the WFS system. While in the WFS system, small loudspeakers generate a sound movement or localization precisely, each speaker in the 8 channel spreads sounds over larger angles. Such characters that the 8-channel configuration provide make it possible to think of ‘zones’, that are varying their shapes over time. Moving sources are possible as well, and there is a variety method to create a specific movement such as Ambisonic panning, equal power azimuth panning, and vector-based amplitude panning.

Figure 9. Stereophonic configuration formulated with vectors.[12]
Before making a choice between different panning implementations, it was necessary to make a comparison between them. In SuperCollider, I have compared BiPanB2 / DecodeB2, a 2D Ambisonic B-format panner, PanAZ, a Multichannel equal power azimuth panner and VBAP, a vector-based amplitude panning. The tests are made with simple trajectories: a straight line crossing the space, a circular motion, and a figure of eight motion. A Doppler effect is applied to each method, and white noise was used as a sound source. In the following chapter the application of the Doppler effect is explained.
The experiment gives a rather unclear answer, meaning that each panning method did not provide a distinctive difference in the spatial perception. Then the choice was made based on the feasibility to alternate the speaker configurations. This means that a different shape of the 8-loudspeaker configuration in a concert hall can be easily adapted. VBAP provides a simple solution. In VBAP, the number of loudspeakers can be arbitrary, and they can be positioned in arbitrary 2-D or 3-D setups. VBAP produces virtual sources that are as precise as is possible with current loudspeaker configuration and amplitude panning methods, since it uses at one time, the minimum number of loudspeakers needed; one, two, or three[13]. It uses a buffer to store the speaker configuration with an array. For example, an array of [0, 45, 90, 135, 180, -135, -90, -45] implies the angles of each speaker and the order of the speaker array, starting from the center front (0), front-right (45), center-right (90), and so on. Simply by changing the values of the angles, every module with a VBAP is adapted to a new configuration, as they share the same buffer.
Zones and density
Another possibility that the 8-channel configuration provides, is to make pairs with different numbers of speakers. A pair of two (Figure 10b), three and four (Figure 10a) and combinations of different pairs can create different sized spatial zones. Unlike the static sources in the WFS system, which are omni-directional, such pairs would create a rather ambiguous spatial zone of a sound that can also be directional. When each pair of the speakers share certain areas, a possibility to differentiate the density of the area also appears. In this piece, two pairs of stereos (front and rear) and four pairs of four speakers (two diamonds, and left and right side) are used.


Figure 10a the ‘Double-diamond’ setup, 10b pairs of stereo setup[14]
There are four moving trajectories designed and used in the piece (Figure 11a-11d). With a rather simple figure of motion, it is possible to change the amount of spread in VBAP, which can be set between 0 and 100. This value indicates how far a spot can be spread over other loudspeakers, and it blurs the localization of the sound, yet covers a larger area. By modulating this value over time, the figure of motion morphs, as shown in Figure 11a, 11b, and 11c. Figure 11d is not a moving source, but sound sources have a fixed position in each loudspeaker. Sounds may come from in all directions. By differentiating the amplitude of each speaker at a different moment, a spatial motion can be created. There are two random trajectories used, each of which has different interpolations, such as a linear and exponential, and has the same principle of using different spread values at different moments in time.

Figure 11a, 11b, 11c, 11d Spatializations with width and spread value changes. Circular(a), Straight line(b), figure of eight(c), and direct 8 channels(d)
Speed of spatial movements, Doppler effect, and rhythm
The spatializations mentioned above share a VBAP buffer. The possibility of sharing values between modules is due to the global variables. In a similar manner, those spatial modules can share common control values, and it opens up a unified value between the very different, moving characters. Each spatial module includes ‘Doppler effect’ calculation using a Delay and a Low Pass Filter, whose control parameters are mapped to the distance of the moving sound source, and the speed of the movement. Doppler effect is the change in frequency of a wave, in relation to an observer who is moving relative to the wave source[15]. It is a natural phenomenon that is happening when a sound around a listener is moving at a speed from one distance to another. The speed of sound and the rate of change in distance between the sound source and the listener are important factors responsible for the shift in the pitch of the sound. In the WFS system, the doppler effect is already integrated, but for this piece an implementation of the doppler effect is essential for the movement to sound realistically vivid.
Those different spatial motions start moving slowly from the beginning of the piece, and over time their speeds change together. Towards the end of the piece, the speed gets faster and faster, so that all of the incoming signals are shaped by the Doppler effect, and it can be described as being modulated and re-textualized. Then, those altered textures are heard as a rhythm. The music begins with the simple tone of the audio feedback, and evolves into complex sonic layers created by sets of modules, but it ends with an almost repetitive rhythm that is created by spatial movements. The unification of the speed changes in each spatial module is therefore crucial to the piece.
Module trees and cloud of sounds
In the first piece, the module trees are constructed in parallel at each input, and they have the same module structure. In the second piece, the tree structures between the two inputs are slightly different, and have more shared modules. That is because the WFS system offers an audible distinction between different sound layers, but in the 8 channel systems, each channel is more diffused. Accordingly, it is logical to reduce the number of module layers and have more reinforcement from two inputs together. Additionally, there are more dependencies between modules, meaning that the sound passes through a series of modules, and the outcoming sounds from them influence what happens next. Such structures invite a transformation of sound, whose original colors and shapes are more altered, and contribute to becoming a more unique sound texture. Each module, as in the first piece, is triggered over time. In Figure 12, the left and right sides of modules for each input channel are triggered first, and then move to the center modules. Also, some of the modules are turned off sequentially.
In the halfway point of the piece, all the modules are already triggered, and the second half of the piece runs variations of the modules. Parameter values in modules, together with the speed of the spatializations, are being changed by the scheduler in Routine. These long variations of the modules make it possible to perceive an organic growth and morphosis of the cloud over time. While the complexity of the WFS system is created rather by interwoven layers of sounds in space, the 8 channel modules turn all of the sound layers into a large cloud. A more diffusional character of the sound system can create a heavy sound mass, but can fill the space and be moved around by given spatializations. Some modules, with a more distinctive texture, can still be heard, individually articulating in the cloud.
The spatial modules (Figure 13) are executed from the beginning of the piece. Whether or not any incoming signal enters into a module, they stay at the bottom of the tree structure, waiting for the incoming signals. Figure 13 shows the shared values between the modules: speed, spread multiplier, and distance.

Experiments and performances
The piece was tried out in three different locations with different volumes: Wave Field Synthesis Studio(Media 4), a studio, New Music Hall (Media 5), a medium sized hall with a high ceiling, and Arnold Schönbergzaal (Media 6), a big concert hall. In order to make a fair comparison between different halls, the input gain in the mixer is always set to +15dB, and the output level to 0dB. Tuning of the input and output level is made within Routine, where no additional level control is necessary. Those fixed levels in the mixer are a reference point, and the engineer can make it slightly louder or softer depending on the acoustics of the hall when the piece is heard. However, during the three experiments, it was unnecessary to change the input or the output levels.
A clear logic between the size of the hall and the pitch of feedback sound has not been found; they were simply different. Each location has different loudspeakers whose characters are different as well. The size of the space does not indicate the pitch. However, the difference in the sound reflection influences the longevity of the feedback sound. The studio Wave Field Synthesis Studio has acoustic panels on the wall that reduces reflections of sound, so the room is quite ‘dry’, as well as the New Music Hall by curtains. The experiment started with two input channels to the left and right side of the speaker, only without any movement of sound, and the feedback sound was easily stuck into a too dominant frequency that was difficult to make the pitch change. Slowly moving sound through each speaker in time and a low level of feedback sound were necessary to change the pitch. After finding a proper tuning, I used this level as the standard level for the other halls, which was probably not the best option. This opens up for further experimentation in the future, with a deeper focus on revealing resonant frequencies of a room.
The location of the performer may differ as well, as does the sitting position of the listener. The performer is sitting towards the front speakers in the Wave Field Synthesis Studio, in the New Music Lab closer to the back speakers facing the front speakers, and in the Arnold Schönbergzaal closer to the front speakers facing the back speakers. The flexibility of the performer’s position can be utilized, but a more significant development, with regard to the feedback sound, is found when the performer is closer to the front speakers (or in front of a set of two speakers in stereo.) This position yields a greater impact from the spatial relationship between the microphones and speakers, and therefore the gestures of hands can be more subtle, and pitch and dynamic changes are heard immediately.
After the first public performance in the Arnold Schönbergzaal, I could hear a number of perspectives from the audience. Among them the visual impact of the performance is significant. The relationship between the hand gesture and the musical development especially at the first half of the piece seems straightforward and strong; the tiny motions of steering the space around the performer call for attention to the changes, and become visual feedback to what they are listening as well as what the performer is listening. It is clear that the interactions between the hand gesture and the sound evolvement are the keys not only for the development of the piece, but also for the listening experience.
Conclusion
The Controlled Ecosystemics system demonstrates that the acoustics of a space, and more specifically its uncontrollable, unpredictable character, can become one of the more important musical elements of a live electronic music composition. It can be achieved by using audio feedback as the main sound source, which, together with the characteristics of loudspeakers and microphones, reveals and interacts with the resonances of a space by means of sound spatializations. The processing modules and trees make possible a metamorphosis of the sounds over time. The dependencies between the modules are the keys to the system that can produce different sounding results in different performing spaces. The incoming feedback sound can contribute to the signal processings throughout the jouney into the trees of modules. The localization of the performer can be flexible and influence varying results as well. The result also depends on the sound spatializations and localizations, in addition to their speed and complexity. The hand gestures of the performer have an important role in the evolution of the piece, and add an important visual element in the presentation, as well as a significant part of the interactions between the feedback sounds, the performing space, and the sound spatializations, any of which cannot simply be prioritized nor dismissed.
The system offers a further development potential to different platforms, such as a sound installation where the audience can influence the movements of sounds, a performance with dancers, and pieces for other multichannel setups. Modules and trees can be composed differently. Also, more flexible modules in the system and a longer duration of the piece can be tested.
The experiments with different multichannel systems and performing spaces have created opportunities to work together and discuss with students.The comparison of different spatialization methods, found knowledge, and tools are useful educational elements, which are beneficial to share with them.
The findings from the two multichannel pieces do not provide a solution for the problems introduced by acoustic spaces in the presentation of live electronic music. However, I hope to have demonstrated that these issues can be embraced within an artistic objective, be a strong inspiration for an artwork to be conceived, and provide opportunities for a variety of approaches, not to find an answer per se, but to question and experiment with a creative mindset.
[1][2][4][5][10] Agostino Di Scipio (2003) “Sound is the interface”: from interactive to ecosystemic signal processing. Organised Sound 8(3)
[3] Anderson, C. (2005) Dynamical Networks of Sonic Interactions. An Interview with Agostino Di Scipio. Computer Music Journal 29(3),
[6] C. van Eck (2017) Between Air and Electricity - Microphones and Loudspeakers as Musical Instruments.
[7] Wikipedia https://en.wikipedia.org/wiki/Audio_feedback#cite_ref-Hodgson_1-0
[8] Game of Life Foundation https://gameoflife.nl/en/about/about-wave-field-synthesis/
[9] SuperCollider Documents https://doc.sccode.org/Classes/Synth.html
[11] Oxford Dictionaries https://www.lexico.com/definition/gyroscope
[12] V. Pulkki (1997) A Virtual Sound Source Positioning Using Vector Base Amplitude Panning
[13] V. Pulkki http://legacy.spa.aalto.fi/research/cat/vbap/
[14] J, Fielder (2016) A History of the Development of Multichannel Speaker Arrays for the Presentation and Diffusion Acousmatic Music
[15] Wikipedia https://en.wikipedia.org/wiki/Doppler_effect#cite_note-Giordano-3